For the next paper in my Paper Implementation series, I picked the Dynamo 2007 paper by Amazon. I had a really good time with this one. Large scale distributed systems always fascinate me , how do you handle that much data, across that many machines, and keep it working when things inevitably break? The Dynamo paper has a clear answer, and it keeps repeating it in case you miss it: eventual consistency. It’s genuinely one of the best-written systems papers I’ve come across.
Before getting into how I built it, I want to say something about why Elixir felt like the right choice here. The BEAM , the virtual machine underneath Elixir and Erlang , was designed by Ericsson for telephone switching systems.
The properties those systems needed are almost word-for-word what Dynamo wants: no single point of failure, isolated crash domains, message-passing between processes, and graceful degradation under load.
Although these are very sound reasons as in themselves, I actually really wanted to use elixir for my paper implementation series haha I just find this language really elegant and it’s growing on me.
What Dynamo is actually solving
The paper opens with a very concrete problem: Amazon’s shopping cart must always accept items. A customer adding something to their cart cannot see an error because a storage node happened to go down. The business cost of that failure is real and measurable. The cost of showing a slightly stale cart? Basically zero.
That tradeoff is what Dynamo is built around. It sits firmly in the AP corner of the CAP theorem , availability and partition tolerance, at the cost of strong consistency. The paper doesn’t pretend this tradeoff doesn’t exist. It just argues, correctly, that for a significant class of problems, availability is worth more than consistency.
The way it achieves this is through eventual consistency , all writes will eventually reach all replicas, conflicts will eventually be resolved, and the system will eventually converge on a single value. The word “eventually” is doing a lot of work there, and the rest of the paper is about making “eventually” as fast and reliable as possible.
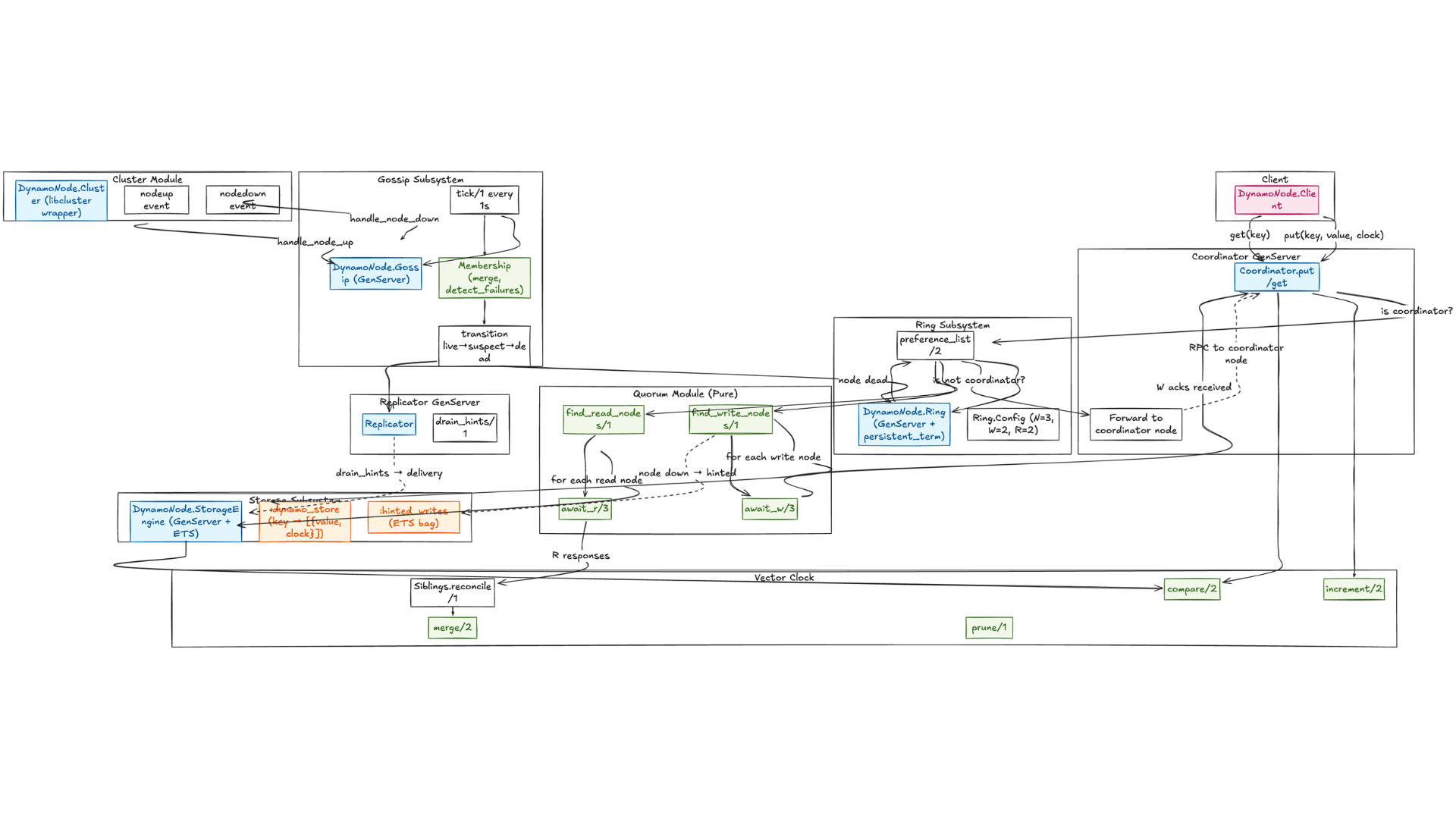
Project Structure
Before diving into the implementation, here’s how the code is organized:
lib/dynamo_node/
├── application.ex # OTP Application - supervision tree
├── cluster.ex # libcluster wrapper - node lifecycle events
├── client.ex # Public API for external callers
├── replicator.ex # Handles hinted handoff drain
├── ring/
│ ├── ring.ex # GenServer - consistent hash ring
│ └── config.ex # N/W/R quorum configuration
├── coordinator/
│ ├── coordinator.ex # GenServer - write/read coordination
│ └── quorum.ex # Pure - node selection, quorum logic
├── gossip/
│ ├── gossip.ex # GenServer - periodic peer exchange
│ └── membership.ex # Pure - merge + failure detection FSM
├── storage/
│ ├── storage_engine.ex # GenServer - ETS owner
│ └── hinted_write.ex # Pure - hinted write struct + ETS helpers
└── vector_clock/
├── vector_clock.ex # Pure - clock operations
└── siblings.ex # Pure - sibling reconciliation
The supervision tree in application.ex defines the startup order, which actually matters a lot here:
defmodule DynamoNode.Application do
use Application
def start(_type, _args) do
children = [
DynamoNode.Ring, # 1. Ring first - everything routes through it
DynamoNode.StorageEngine, # 2. Storage next - writes need somewhere to go
DynamoNode.Gossip, # 3. Gossip needs Ring for node events
DynamoNode.Replicator, # 4. Replicator drains hints on recovery
DynamoNode.Coordinator, # 5. Coordinator handles get/put
DynamoNode.Cluster, # 6. Cluster - libcluster event relay
{Task.Supervisor, name: DynamoNode.Replicator.TaskSupervisor}
]
opts = [strategy: :one_for_one, name: DynamoNode.Supervisor]
Supervisor.start_link(children, opts)
end
end
Ring starts first because all routing decisions depend on it. Storage needs to be up before Gossip starts because nodes joining the ring need somewhere to store their membership entry. The Coordinator comes last because it depends on everything else.
The ring: consistent hashing
The first big idea in Dynamo is how it distributes keys across nodes. The naive approach , hash(key) rem n_nodes , breaks badly when you add or remove a node, because nearly every key maps to a different node and you get a total reshuffling of data.
Consistent hashing solves this by mapping both keys and nodes onto a circular hash ring. A key is owned by the first node you encounter walking clockwise around the ring. When you add a node, only the keys between it and its predecessor need to move. When you remove a node, only its keys move to its successor. Everything else stays put.
Dynamo takes this one step further with virtual nodes (vnodes). Instead of placing each physical machine at a single point on the ring, each machine claims multiple positions , 128 by default in my implementation. Two nice things happen. First, load naturally balances because each machine owns multiple non-contiguous arc segments. Second, adding a new machine is gradual: it takes small slices from many existing nodes rather than one big chunk from one.
@vnodes Config.vnodes_per_node() # Default: 128
defp expand_nodes(nodes) do
Enum.flat_map(nodes, fn {node_name, vnode_count} ->
Enum.map(1..vnode_count, fn i ->
vnode_key = "#{node_name}:#{i}"
{Hash.of(vnode_key), node_name}
end)
end)
end
Each virtual node gets a unique key like "node_a:1", "node_a:2", and so on, that key is hashed to produce a position on the ring. The paper recommended 100-200 virtual nodes per physical node, and 128 sits comfortably in that range.
What I had to be careful about was building the preference list correctly , you walk clockwise from a key’s position and collect the first N distinct physical nodes, not just N vnodes. Since the same physical host can occupy multiple ring positions, you can easily end up with three vnodes all pointing at the same machine, which gives you zero actual redundancy.
defp do_preference_list(nodes, _table, _generation, key, _requested_n) do
expanded = expand_nodes(nodes)
sorted = Enum.sort_by(expanded, fn {hash, _} -> hash end)
target_hash = Hash.of(key)
{before, after_bucket} = Enum.split_while(sorted, fn {hash, _} -> hash <= target_hash end)
rotated = after_bucket ++ before
Enum.reduce(rotated, {MapSet.new(), []}, fn {hash, node}, {seen_acc, result_acc} ->
if node in seen_acc do
{seen_acc, result_acc}
else
{MapSet.put(seen_acc, node), [{hash, hash, node} | result_acc]}
end
end)
|> elem(1)
end
Zero-copy reads with :persistent_term
Every get and put needs to call Ring.preference_list/2. If that required a GenServer call, you’d serialize all routing decisions through a single process , a bottleneck that gets worse under load.
Instead, the ring state is written to :persistent_term after every mutation:
defp sync_persistent(state) do
:persistent_term.put(@persistent_term_key, {
state.nodes,
state.table,
state.generation,
state.sizes
})
state
end
Now preference_list/2 reads directly from persistent term without any process communication:
def preference_list(key, n) do
case :persistent_term.get(@persistent_term_key, nil) do
nil ->
[]
{nodes, table, generation, _sizes} ->
do_preference_list(nodes, table, generation, key, n)
end
end
Ring changes are infrequent enough that the write cost is negligible. The hot path , lookups on every get and put , costs essentially nothing.
Vector clocks: tracking what happened when
This is the part that requires the most careful thinking. When the system is “always writable”, two nodes can independently accept conflicting writes to the same key. How do you know which one came first? How do you even know if they’re in conflict at all, versus one simply superseding the other?
You can’t use wall clocks. NTP drift across a distributed cluster is enough to cause real ordering bugs, and the paper is explicit about this. Dynamo uses vector clocks instead , a map from node identifiers to counters. Every write increments the counter for the writing node.
@type node_id :: atom()
@type clock :: %{node_id() => {counter :: pos_integer(), ts :: integer()}}
def new, do: %{}
def increment(%{} = clock, node_id) do
ts = System.system_time(:millisecond)
{counter, _} = Map.get(clock, node_id, {0, 0})
Map.put(clock, node_id, {counter + 1, ts}) |> prune()
end
The clock is a map from node IDs to pairs of {counter, timestamp}. The timestamp is used only for pruning, not for causal ordering. All causal reasoning uses counters only, that distinction matters.
When you compare two versions of an object, you compare their clocks component by component:
def compare(%{} = clock_a, %{} = clock_b) do
all_nodes = MapSet.union(MapSet.new(Map.keys(clock_a)), MapSet.new(Map.keys(clock_b)))
{a_strict, b_strict} =
Enum.reduce(all_nodes, {0, 0}, fn n, {a_s, b_s} ->
a_c = elem(Map.get(clock_a, n, {0, 0}), 0)
b_c = elem(Map.get(clock_b, n, {0, 0}), 0)
cond do
a_c > b_c -> {a_s + 1, b_s}
b_c > a_c -> {a_s, b_s + 1}
true -> {a_s, b_s}
end
end)
cond do
a_strict > 0 and b_strict == 0 -> :after
b_strict > 0 and a_strict == 0 -> :before
a_strict == 0 and b_strict == 0 -> :equal
true -> :concurrent
end
end
The result is one of four things: :after (A dominates B), :before (B dominates A), :equal (same history), or :concurrent , the interesting case, where neither clock dominates the other. That last case means the writes happened independently and are a genuine conflict.
Merging clocks is straightforward , take the maximum counter for each node:
def merge(%{} = clock_a, %{} = clock_b) do
Map.merge(clock_a, clock_b, fn _node, {a_c, a_ts}, {b_c, b_ts} ->
if a_c >= b_c, do: {a_c, a_ts}, else: {b_c, b_ts}
end)
end
I have property tests on compare/2 using stream_data that verify the algebraic laws across thousands of generated inputs: transitivity, antisymmetry, reflexivity, and that increment always produces an :after result relative to the original clock.
# Commutativity
check all(a <- clock_gen(), b <- clock_gen()) do
assert VectorClock.merge(a, b) == VectorClock.merge(b, a)
end
# Transitivity
check all(base <- clock_gen(), node_a <- node_id_gen(), node_b <- node_id_gen()) do
c = VectorClock.increment(base, node_a)
b = VectorClock.increment(c, node_b)
a = VectorClock.increment(b, node_b)
assert VectorClock.compare(a, b) == :after
assert VectorClock.compare(b, c) == :after
assert VectorClock.compare(a, c) == :after
end
Pruning to prevent clock explosion
In a system running for years with thousands of nodes touching millions of keys, vector clocks grow unboundedly without intervention. Every node that ever coordinated a write on a key adds an entry to its clock.
The prune/1 function trims the oldest entries when the clock exceeds 50 entries:
@max_entries 50
def prune(clock) when map_size(clock) <= @max_entries, do: clock
def prune(clock) do
clock
|> Enum.sort_by(fn {_, {_, ts}} -> ts end, :desc)
|> Enum.take(@max_entries)
|> Map.new()
end
This can theoretically turn a happens-before relationship into an apparent concurrent one, creating spurious siblings. The threshold is a tradeoff, and the paper is honest that they haven’t fully solved it. The key thing: timestamps here are for LRU-style eviction only, never for causal ordering.
NRW: the consistency knob
With N replicas of every key, Dynamo gives you three integers to tune the tradeoff between consistency and availability: N (total replicas), R (how many replicas must respond to a read), and W (how many must acknowledge a write).
My defaults are N=3, W=2, R=2. The critical property is R + W > N. When this holds, any read quorum and any write quorum share at least one node , meaning a read will always encounter the most recent write. When it doesn’t hold (say, R=1, W=1), you get maximum availability but you might read stale data.
defmodule DynamoNode.Ring.Config do
@doc "Replication factor - number of replicas per key."
def n, do: Application.get_env(:dynamo_node, :n, 3)
@doc "Write quorum - must ack from this many replicas before returning to client."
def w, do: Application.get_env(:dynamo_node, :w, 2)
@doc "Read quorum - must collect this many replicas before reconciling."
def r, do: Application.get_env(:dynamo_node, :r, 2)
@doc "Virtual nodes allocated per physical node in the consistent hash ring."
def vnodes_per_node, do: Application.get_env(:dynamo_node, :vnodes_per_node, 128)
@doc "Max time (ms) to wait for W acknowledgements on a write."
def put_timeout, do: Application.get_env(:dynamo_node, :put_timeout, 5_000)
@doc "Max time (ms) to wait for R responses on a read."
def get_timeout, do: Application.get_env(:dynamo_node, :get_timeout, 5_000)
end
All values can be overridden at runtime via Application.put_env/3 without recompilation. This is handy for testing , you can set w=1 and r=1 to test with a single node.
The coordinator sends the write to all N nodes simultaneously and waits for W acknowledgments. Once W arrive, it responds to the client. The remaining writes finish in the background.
Implementing await_w correctly in Elixir is interesting. You don’t want Task.await_many because that blocks until all tasks complete. You want Task.yield_many in a loop so you can return as soon as W acks arrive and cancel the remaining tasks:
defp do_await(tasks, remaining, timeout, acc) do
results = Task.yield_many(tasks, timeout)
completed =
Enum.reduce(results, [], fn
{_task, {:ok, {:ok, result}}}, acc -> [result | acc]
{_task, {:ok, :ok}}, acc -> [:ok | acc]
{_task, {:ok, other}}, acc -> [other | acc]
{_task, {:exit, _}}, acc -> acc
{_task, nil}, acc -> acc
end)
pending = for {task, nil} <- results, do: task
for t <- pending, do: Task.shutdown(t, :brutal_kill)
if length(completed) >= remaining do
{:ok, Enum.reverse(completed) |> Enum.take(remaining)}
else
{:error, :insufficient_acks}
end
end
When tasks time out (nil result), we brutal-kill them. This is aggressive but correct , we’ve already decided we don’t need their result, and letting them linger wastes resources.
Sloppy quorum: staying writable through failures
When a node in the preference list is unreachable, the coordinator doesn’t give up. It finds the next healthy node on the ring and sends the write there instead, tagged with a hint: “this data really belongs to node X.”
defp do_find_write_nodes([{_hash, _vnode_id, node} | rest], live_nodes, remaining, acc) do
if node in live_nodes do
do_find_write_nodes(rest, live_nodes, remaining - 1, [{node, :normal} | acc])
else
intended_node = node
{filled, fallbacks} = Enum.split_while(acc, fn {n, _type} -> n in live_nodes end)
new_fallbacks = [{node, {:hinted, intended_node}} | fallbacks]
do_find_write_nodes(rest, live_nodes, remaining - 1, filled ++ new_fallbacks)
end
end
The algorithm splits the accumulated nodes into “filled” (already on live nodes) and “fallbacks”, then puts the hinted write at the front of the fallbacks list. This ensures hinted writes get delivered before normal writes to the same node during recovery.
The write completes from the client’s perspective. The cluster is temporarily inconsistent, but that inconsistency is tracked and bounded. When the failed node recovers, gossip fires a node_recovered event and the Replicator drains the hinted writes:
defp drain_hints(node) do
hints = HintedWrite.fetch_all(node)
Enum.each(hints, fn hint ->
result =
try do
:rpc.call(hint.intended_node, StorageEngine, :local_put,
[hint.key, hint.value, hint.clock], @drain_timeout)
rescue
_ -> {:error, :rpc_error}
end
case result do
{:ok, _clock} -> HintedWrite.delete(hint.ref)
_ -> :skip
end
end)
end
The drain is idempotent. If it fails partway through , say the target node crashes again mid-drain , the remaining hints stay in the table and the next recovery attempt picks them up.
The hinted write structure
Hints are stored in an ETS bag table:
defmodule DynamoNode.HintedWrite do
@enforce_keys [:key, :value, :clock, :intended_node]
defstruct @enforce_keys ++ [ref: nil, inserted_at: nil]
@type t :: %__MODULE__{
key: term(),
value: term(),
clock: DynamoNode.VectorClock.clock(),
intended_node: node(),
ref: reference(),
inserted_at: integer()
}
def create_table do
case :ets.info(@table_name) do
:undefined -> :ets.new(@table_name, [:named_table, :bag, {:keypos, 2}])
_ -> @table_name
end
end
def store(%__MODULE__{key: key, value: value, intended_node: intended_node, clock: clock}) do
record = {key, value, intended_node, clock, make_ref(), System.system_time(:millisecond)}
:ets.insert(@table_name, record)
:ok
end
end
A bag table allows multiple hints for the same key, which matters because a node might be down long enough for several writes to queue up for it.
The coordinator: orchestrating get and put
The coordinator is where everything comes together. It’s a GenServer that handles both local and remote get/put requests, determines the right coordinator node, fires off RPCs, and handles the response processing.
defmodule DynamoNode.Coordinator do
alias DynamoNode.{VectorClock, Ring, StorageEngine, HintedWrite}
alias DynamoNode.VectorClock.Siblings
alias DynamoNode.Coordinator.Quorum
alias DynamoNode.Ring.Config
@type put_result :: {:ok, VectorClock.clock()} | {:error, atom()}
@type get_result ::
{:ok, any(), VectorClock.clock()}
| {:siblings, [{any(), VectorClock.clock()}], VectorClock.clock()}
| {:error, atom()}
The coordinator identity rule is load-bearing. The coordinator for a key must always be the first node in its preference list. If you let any node handle a write locally, you end up with different nodes producing different vector clocks for the same key, and conflict detection breaks in subtle ways:
defp get_coordinator(key) do
[first | _] = Ring.preference_list(key, 1)
{_hash, _vnode_id, node} = first
node
end
The put path
defp do_put(key, value, context_clock) do
write_nodes = Quorum.find_write_nodes(key)
w = Config.w()
tasks =
for {node, write_type} <- write_nodes do
Task.async(fn ->
case write_type do
:normal ->
:rpc.call(node, StorageEngine, :local_put, [key, value, context_clock])
{:hinted, intended_node} ->
result = :rpc.call(node, StorageEngine, :local_put, [key, value, context_clock])
{result, intended_node}
end
end)
end
case Quorum.await_w(tasks, w, Config.put_timeout()) do
{:ok, acks} ->
final_clock = extract_clock_from_acks(acks, key, value, context_clock)
{:ok, final_clock}
{:error, :insufficient_acks} ->
{:error, :insufficient_acks}
end
end
For hinted writes, we store the hint in ETS for later delivery:
defp store_hint(key, value, context_clock, intended_node) do
hint = %HintedWrite{
key: key,
value: value,
clock: context_clock,
intended_node: intended_node
}
HintedWrite.store(hint)
end
The get path
defp do_get(key) do
read_nodes = Quorum.find_read_nodes(key)
r = Config.r()
tasks =
for node <- read_nodes do
Task.async(fn -> :rpc.call(node, StorageEngine, :local_get, [key]) end)
end
case Quorum.await_r(tasks, r, Config.get_timeout()) do
{:ok, responses} -> process_read_responses(key, responses)
{:error, :insufficient_acks} -> {:error, :insufficient_acks}
end
end
Processing read responses
defp process_read_responses(key, responses) do
all_siblings =
Enum.flat_map(responses, fn
siblings when is_list(siblings) -> siblings
{:ok, siblings} -> siblings
:not_found -> []
end)
case all_siblings do
[] ->
{:error, :not_found}
siblings ->
reconciled = Siblings.reconcile(siblings)
case reconciled do
[{value, clock}] ->
schedule_read_repair(key, responses, value, clock)
{:ok, value, clock}
multiple ->
merged_clock = multiple
|> Enum.map(fn {_, c} -> c end)
|> Enum.reduce(%{}, &VectorClock.merge/2)
{:siblings, multiple, merged_clock}
end
end
end
Siblings: How conflicts are handled
When a read returns multiple concurrent versions, Dynamo calls them siblings. The system returns all of them to the client rather than auto-merging. This is deliberate: automatic strategies like last-write-wins can silently discard data, and Dynamo considers that unacceptable.
The reconciliation logic is pretty clean. Flatten all versions from R replicas into a single list, deduplicate identical pairs, then discard any version whose clock is dominated by another:
defmodule DynamoNode.VectorClock.Siblings do
@type version :: {value :: term(), clock :: DynamoNode.VectorClock.clock()}
@type sibling_lists :: [version()]
def reconcile(sibling_lists) do
sibling_lists
|> List.flatten()
|> Enum.uniq_by(fn {value, clock} -> {value, clock} end)
|> reject_dominated()
end
defp reject_dominated(versions) do
Enum.reject(versions, fn v_current ->
Enum.any?(versions, fn v_other ->
v_other !== v_current and
DynamoNode.VectorClock.compare(elem(v_other, 1), elem(v_current, 1)) == :after
end)
end)
end
end
What remains is either a single version (clean read) or multiple concurrent versions that the client must merge. My Client module returns them as {:siblings, [{value, clock}], merged_clock}. The client merges however makes sense for their domain , union for shopping carts, last-write-wins for session data if you’re willing to accept the data loss , and writes back with the merged clock. That write then dominates all the siblings and cleans up the conflict.
Read repair: fixing stale replicas opportunistically
After every successful read, if some replicas returned stale data, the coordinator asynchronously pushes the correct value back to them. This is read repair , a continuous, low-overhead convergence mechanism that keeps replicas in sync without needing a dedicated anti-entropy process.
defp schedule_read_repair(key, responses, reconciled_value, reconciled_clock) do
for response <- responses do
case response do
{:ok, siblings} ->
Task.start(fn ->
stale? = Enum.all?(siblings, fn {_, clock} ->
VectorClock.compare(clock, reconciled_clock) in [:before, :equal]
end)
if stale? && reconciled_value do
StorageEngine.local_put(key, reconciled_value, reconciled_clock)
end
end)
_ -> :skip
end
end
end
The logic checks if a replica’s clock is dominated by (:before) or equal to (:equal) the reconciled clock. If so, the replica is stale and needs updating. It runs as a detached, fire-and-forget task , the client is not blocked on it.
The storage engine: ETS all the way down
Dynamo’s storage layer uses ETS exclusively. No disk, no external database. ETS tables are in-memory, survive process crashes as long as the VM stays up, support concurrent reads, and have zero external dependencies. The durability story is: replicas are your durability. If you lose a node entirely, you have N-1 other copies.
When storing a value, the full sibling management algorithm runs:
defmodule DynamoNode.StorageEngine do
use GenServer
alias DynamoNode.VectorClock
@table_name :dynamo_store
@impl true
def init(_opts) do
if :ets.info(@table_name) == :undefined do
:ets.new(@table_name, [:named_table, :set, {:keypos, 1}, :protected])
end
if :ets.info(:hinted_writes) == :undefined do
:ets.new(:hinted_writes, [:named_table, :bag, {:keypos, 5}, :public])
end
{:ok, %__MODULE__{}}
end
def handle_call({:local_put, key, value, context_clock}, _from, state) do
current_siblings = case :ets.lookup(@table_name, key) do
[{^key, siblings}] -> siblings
[] -> []
end
surviving = Enum.reject(current_siblings, fn {_v, clock} ->
VectorClock.compare(context_clock, clock) in [:after, :equal]
end)
coordinator = Node.self()
new_clock = context_clock |> VectorClock.increment(coordinator) |> VectorClock.prune()
new_siblings = [{value, new_clock} | surviving]
:ets.insert(@table_name, {key, new_siblings})
{:reply, {:ok, new_clock}, state}
end
end
Read existing siblings. Discard any whose clock is dominated by the incoming context. Increment the clock to record this write. Prepend the new version. Write back.
If context_clock is empty (%{}), it dominates nothing, so all existing siblings survive. This is a blind write , it always creates a sibling if concurrent versions exist. This is correct and intentional.
Gossip: knowing who’s alive
In a masterless system there’s no coordinator to ask “which nodes are up?” Each node maintains its own view of the cluster through a gossip protocol.
Every second, each node increments its own heartbeat, picks a random live peer, sends its full membership table, and runs failure detection:
defmodule DynamoNode.Gossip do
alias DynamoNode.Gossip.Membership
@gossip_interval 1_000
defp tick(state) do
membership = state.membership
my_node = node()
now = now_ms()
my_entry = Map.get(membership, my_node)
new_heartbeat = (my_entry && my_entry.heartbeat + 1) || 1
new_membership = Map.put(membership, my_node, %{
status: :alive,
heartbeat: new_heartbeat,
updated_at: now
})
peers = live_peers(new_membership)
if peers != [] do
peer = Enum.random(peers)
GenServer.cast({__MODULE__, peer}, {:gossip, new_membership})
end
new_membership = Membership.detect_failures(new_membership, now)
handle_failures(membership, new_membership)
timer_ref = schedule_tick()
%{state | membership: new_membership, timer_ref: timer_ref}
end
end
Using cast (async) for gossip means slow peers don’t affect local operations. The tradeoff is that gossip can be lost under heavy load, but that’s fine the next tick will carry the information.
The membership state machine
Failure detection is a state machine per node: :alive -> :suspect -> :dead. A node transitions to suspect if its heartbeat hasn’t been updated in 5 seconds, and to dead after 30 seconds total silence:
defmodule DynamoNode.Gossip.Membership do
@suspect_timeout 5_000 # alive -> suspect after 5s silence
@dead_timeout 30_000 # suspect -> dead after 30s total silence
@type status :: :alive | :suspect | :dead
@type member :: %{status: status(), heartbeat: pos_integer(), updated_at: integer()}
def transition(%{status: status, updated_at: updated_at} = member, now_ms) do
silent_for = now_ms - updated_at
new_status = cond do
status == :alive and silent_for > @suspect_timeout -> :suspect
status == :suspect and silent_for > @dead_timeout -> :dead
true -> status
end
%{member | status: new_status}
end
end
On a :dead transition, two things happen: Ring.remove_node/1 evicts the node’s vnodes from the ring, and Replicator.node_down/1 cancels any in-flight drain tasks:
defp handle_failures(old_membership, new_membership) do
old_dead = dead_nodes(old_membership)
new_dead = dead_nodes(new_membership)
Enum.each(new_dead -- old_dead, fn node ->
try do
DynamoNode.Ring.remove_node(node)
catch
_, _ -> :ok
end
try do
DynamoNode.Replicator.node_down(node)
catch
_, _ -> :ok
end
end)
end
Merging membership views
There’s one subtle rule in Membership.merge/2 worth flagging: a remote gossip message must never override your own membership entry. A lagging or partitioned node might think you’re dead and gossip that to the cluster. You always preserve mine[node()] unconditionally:
def merge(mine, theirs) when is_map(mine) and is_map(theirs) do
my_node = node()
Map.merge(mine, theirs, fn
# Own node is NEVER overridden by remote
# Prevents malicious/lagged nodes from marking us as dead
^my_node, _local, _remote ->
Map.get(mine, my_node)
# Higher heartbeat wins for all other nodes
_node, local, remote ->
if local.heartbeat >= remote.heartbeat, do: local, else: remote
end)
end
This was easy to get wrong in the first pass. Your own view of your status is always authoritative.
Trying it out
Dynamo needs a cluster to operate properly because it uses quorum-based replication. With the default N=3, W=2, R=2 configuration, you need at least 2 live nodes for writes to succeed (and ideally 3 for full durability).
For single-node testing, set w=1 and r=1:
iex -S mix
Then in the IEx shell:
# Lower the quorum for single-node testing
Application.put_env(:dynamo_node, :w, 1)
Application.put_env(:dynamo_node, :r, 1)
# Do a blind write
{:ok, clock} = DynamoNode.Client.put("user:42", %{name: "Alice", email: "alice@example.com"}, %{})
# Read it back
{:ok, data, _clock} = DynamoNode.Client.get("user:42")
# => %{name: "Alice", email: "alice@example.com"}
# Update with the returned clock (causal write)
{:ok, new_clock} = DynamoNode.Client.put("user:42", %{name: "Alice", email: "alice@company.com"}, clock)
# Two blind writes to the same key create siblings
{:ok, _c1} = DynamoNode.Client.put("cart:1", %{items: ["book"]}, %{})
{:ok, _c2} = DynamoNode.Client.put("cart:1", %{items: ["shirt"]}, %{})
# Now a subsequent read returns siblings:
{:siblings, versions, merged_clock} = DynamoNode.Client.get("cart:1")
# => {:siblings, [{%{items: ["shirt"]}, clock2}, {%{items: ["book"]}, clock1}], merged_clock}
# Merge them (cart merge = union of items):
merged = %{items: ["book", "shirt"]}
DynamoNode.Client.put("cart:1", merged, merged_clock)
# Clean read after merge:
DynamoNode.Client.get("cart:1")
# => {:ok, %{items: ["book", "shirt"]}, new_clock}
The DynamoNode.TestCluster helper provides start/1, partition/1, heal/1, and rpc/4 utilities for multi-node testing:
# Start a 3-node cluster
{:ok, nodes} = DynamoNode.TestCluster.start(node_count: 3)
# Partition a node from the cluster
DynamoNode.TestCluster.partition(node_a)
# Heal a partition
DynamoNode.TestCluster.heal(node_a)
# Wait for gossip to converge
DynamoNode.TestCluster.wait_for_convergence(nodes, 10_000)
# RPC to any node
DynamoNode.TestCluster.rpc(node_a, DynamoNode.Coordinator, :put, ["key", "value", %{}])
The test suite runs 163 tests including property-based tests on vector clocks, unit tests on all modules, and integration tests covering coordinator operations, quorum logic, storage engine behavior, and ring membership.
TLDR;
If you came this far, congratulations! Here’s a short gist of what’s happening in this implementation:
| Module | Type | Does |
|---|---|---|
Application | OTP App | Starts the supervision tree in the correct dependency order |
Cluster | GenServer | Wraps libcluster, relays node join/leave events to the ring |
Client | API | Public interface for get/1 and put/3; forwards to the right coordinator |
Replicator | GenServer | Drains hinted writes to recovered nodes; cancels tasks on node death |
Ring | GenServer | Owns the consistent hash ring; publishes state to :persistent_term after every change |
Ring.Config | Config | Holds N, W, R, vnode count, and timeout values; all runtime-overridable |
Coordinator | GenServer | Orchestrates get/put – selects nodes, fires RPCs, waits for quorum |
Coordinator.Quorum | Pure | Node selection logic and await_w/await_r quorum helpers |
Gossip | GenServer | Heartbeats every second, exchanges membership tables with a random peer |
Gossip.Membership | Pure | Merges membership views; runs the :alive -> :suspect -> :dead FSM |
StorageEngine | GenServer | Owns the ETS store; handles sibling management on every local write |
HintedWrite | Pure | Struct and ETS helpers for storing and fetching hints by intended node |
VectorClock | Pure | Clock increment, compare, merge, and pruning operations |
VectorClock.Siblings | Pure | Flattens, deduplicates, and discards dominated versions from R responses |
What I learned
A few things that only became clear during implementation:
The coordinator identity rule is load-bearing. The coordinator for a key must always be the first node in its preference list. If you let any node handle a write locally, you end up with different nodes producing different vector clocks for the same key, and conflict detection breaks in subtle ways. The forwarding logic is not optional.
Stale :persistent_term after a Ring crash is a really nasty bug. If the Ring GenServer crashes and restarts without re-writing :persistent_term in init/1, every other process silently reads the pre-crash ring state. Preference lists are wrong, keys route to dead nodes, and nothing errors loudly. The fix is one line in init/1, but tracking it down took a while.
Gossip and the ring form a feedback loop that needs careful decoupling. Gossip calls Ring.remove_node/1 on death events, which changes the ring, which affects future preference lists. The dependency must be strictly one-way: Gossip -> Ring, never Ring -> Gossip. Testing them decoupled first made this manageable.
Eventual consistency means thinking in states, not operations. The hardest mental shift is accepting that at any given moment the cluster may be in an inconsistent state, and that’s fine. You don’t debug a Dynamo cluster by asking “why did this write not propagate immediately” , you ask “will it propagate eventually, and is conflict detection correct when it does.” Once that clicked, the whole design made much more sense.