Recently, I read the Google File System paper by Ghemawat, Gobioff, and Leung, published at SOSP 2003, and what a fun read it was.
And I asked myself, how much of it can I fit in a single go file, with no external dependencies whatsoever, and it turns out, quite a lot. And that’s what this blog post is about. My implementation of this legendary paper.
1. What Even Is GFS?
Before we dive into code, let me explain what GFS is trying to solve.
Imagine it’s early 2000s Google. You’re crawling the entire web, storing billions of documents, running MapReduce jobs that process terabytes at a time. You need a file system that:
- Runs on cheap commodity hardware, because buying enterprise servers for every node is insane at this scale
- Tolerates failures gracefully, at thousands of machines, something is always broken
- Handles huge files well, not thousands of tiny files, but a smaller number of enormous ones (multi-GB)
- Optimizes for append, not random writes, because most workloads are “write once, read many” pipelines
- Serves hundreds of concurrent clients, without the metadata server becoming a bottleneck
Traditional file systems like POSIX-compatible ones were designed for a single machine. GFS threw those assumptions out and started fresh.
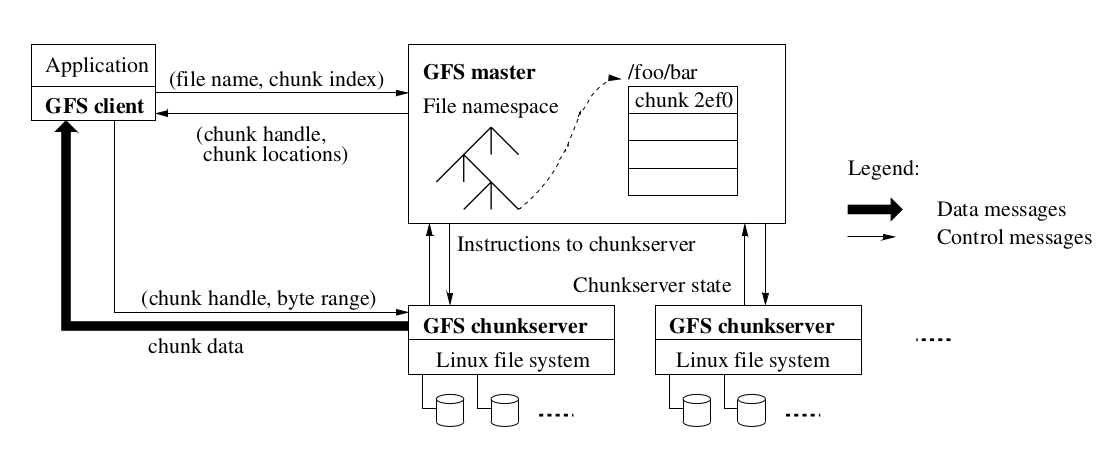
The architecture it landed on is elegant in its simplicity:
- One master that holds all metadata (file names, chunk locations, permissions)
- Many chunkservers that store the actual file data
- Many clients that talk to the master for metadata, then go directly to chunkservers for data
That’s basically the whole system. Let’s see how it’s implemented.
2. Constants and Configuration
Before we get into the fun stuff, let’s talk about the boring-but-important numbers that control how the whole system behaves. Think of these as the dials you’d turn if you were deploying this in production.
const (
DefaultChunkSize = 64 * 1024 * 1024 // 64 MB
BlockSize = 64 * 1024 // 64 KB checksum block
DefaultReplicationFactor = 3
DefaultLeaseTimeout = 60 * time.Second
DefaultHeartbeatInterval = 500 * time.Millisecond
DefaultGCInterval = 10 * time.Second
DefaultGCDelay = 1 * time.Minute
DeletedPrefix = "/.deleted/"
)
These numbers are pulled straight from the paper, and each one has a story.
64 MB chunks is the big one. Traditional file systems use 4KB or 512-byte blocks. GFS uses 64 MB. Why so large? Three reasons:
- Fewer metadata entries at the master, the master can keep everything in RAM because there just aren’t that many chunks
- Clients stay connected to one chunkserver for longer without needing to re-contact the master
- Sequential reads and writes (the dominant workload) get to use persistent connections efficiently
The downside? Small files become a single chunk on one server, and if many clients suddenly want that small file (like a shared binary being deployed across a thousand machines), that one server gets hammered. The paper calls this the “hot spot” problem.
Replication factor of 3 is the classic distributed systems answer to fault tolerance. Lose one server? Fine. Lose two simultaneously? Still fine. It’s the minimum that gives you any real safety.
60-second lease timeout is the lease a chunkserver holds to coordinate writes. We’ll get into leases heavily later.
GCDelay of 1 minute (5 seconds in the demo) is the time between when a file is “deleted” and when its data is actually reclaimed. This implements lazy deletion, which turns out to be a great idea.
The Config struct packages all of these:
type Config struct {
ChunkSize int64
ReplicationFactor int
LeaseTimeout time.Duration
HeartbeatInterval time.Duration
GCInterval time.Duration
GCDelay time.Duration
CheckpointInterval time.Duration
MasterPort int
NumChunkServers int
DataDir string
MaxAppendSize int64
}
Everything is tunable. The main() demo uses a 1 MB chunk size instead of 64 MB just to make testing practical, nobody wants to push 64 MB of data in a demo.
3. Core Data Types
This section defines the fundamental vocabulary of the system, the building blocks every other component uses.
The Chunk Handle
type ChunkHandle uint64
type ChunkVersion uint64
Every chunk in the entire system gets a globally unique 64-bit integer ID called a ChunkHandle. The master hands these out as an incrementing counter using atomic operations. There’s no coordination needed, if the atomic add succeeds, you own that handle.
ChunkVersion is a monotonically increasing number attached to each chunk. Every time a new lease is granted for a chunk, the version bumps. If a chunkserver was offline when this happened, its copy of the chunk is now “stale”, it has an older version number. The master uses this to identify and exclude stale replicas.
Metadata Structures
type FileMetadata struct {
Path string
Chunks []ChunkHandle
IsDeleted bool
DeletedAt time.Time
IsDirectory bool
SnapRefCount map[ChunkHandle]int
}
This is everything the master knows about a file. Notice it’s surprisingly small, just a path, a list of chunk handles, and some flags. No data. The actual bytes live on chunkservers, and the master just tracks where.
SnapRefCount is the copy-on-write reference counter for snapshots. When you snapshot a file, both the original and the snapshot point at the same chunks. Before anyone can write to a shared chunk, it needs to be copied first. This counter tracks how many files are sharing each chunk.
type ChunkMetadata struct {
Handle ChunkHandle
Version ChunkVersion
Primary string
LeaseExpiry time.Time
}
The master’s view of a chunk. Critically, this does not include which servers hold the chunk, that information (chunkLocations) is stored separately and is rebuilt from heartbeats on every restart. The paper explains this design choice: there’s no point trying to keep master and chunkserver in sync about what’s on disk, because the chunkserver is the ground truth. Just ask it.
type LocalChunk struct {
Handle ChunkHandle
Version ChunkVersion
Data []byte
Checksums []uint32
Size int64
}
This is the chunk as it lives on a chunkserver. The Checksums slice holds one CRC32 per 64 KB block. So a 64 MB chunk has 1024 checksums. Every read verifies them, silently catching any disk corruption before it reaches the client.
The Operation Log Entry
type OperationLogEntry struct {
Timestamp time.Time
Op OpType
Path string
Path2 string
Chunk ChunkHandle
Version ChunkVersion
Server string
}
Before the master makes any metadata change, it writes one of these to its operation log. Create file? Log it first. Delete? Log it first. Grant a lease? Log it first.
This is how the master survives crashes. If it dies mid-operation, it replays the log on restart and gets back to exactly the state it was in. The log is the single source of truth for “what really happened.”
4. Checksum Utilities
func computeBlockChecksums(data []byte) []uint32 {
numBlocks := (len(data) + BlockSize - 1) / BlockSize
checksums := make([]uint32, numBlocks)
for i := 0; i < numBlocks; i++ {
start := i * BlockSize
end := min(start+BlockSize, len(data))
checksums[i] = crc32.ChecksumIEEE(data[start:end])
}
return checksums
}
func verifyChecksums(data []byte, checksums []uint32) error {
computed := computeBlockChecksums(data)
for i := range computed {
if computed[i] != checksums[i] {
return fmt.Errorf("checksum mismatch at block %d", i)
}
}
return nil
}
I’m not going to lie, this part is really elegant. How the paper handles data integrity, via checksumming.
The approach is simple but effective. Every 64 KB block of a chunk gets a CRC32 checksum. On every read, the checksums are recomputed and compared. On every write, the affected blocks get their checksums updated.
Why 64 KB blocks instead of checksumming the whole 64 MB chunk? Because reads are often partial, you might only want bytes 4MB through 5MB of a chunk. You’d have to read the whole chunk just to verify a checksum over it. With per-block checksums, you only verify the blocks you actually touch.
The paper notes that corruptions are often detected during reads that would have happened anyway, so the cost of detection is almost zero. Pretty neat, right?
5. The Master Server
The master is the brain of GFS. It holds all metadata but zero file data.
type Master struct {
mu sync.RWMutex
namespace map[string]*FileMetadata
chunkMeta map[ChunkHandle]*ChunkMetadata
nextHandle uint64
chunkLocations map[ChunkHandle]map[string]bool // rebuilt from heartbeats
nsLocks map[string]*sync.RWMutex // per-path locks
opLog []OperationLogEntry // durable change log
leases map[ChunkHandle]*LeaseInfo // active leases
chunkServers map[string]*ChunkServerState // registered servers
serialCounter uint64
config *Config
}
A few things to call out:
namespaceis an in-memory map from file path to metadata. The whole file tree lives in RAM. This is fast and works because, as the paper explains, each file entry is only about 64 bytes.chunkLocationsis explicitly not persisted. It’s rebuilt every time the master restarts by asking each chunkserver “what chunks do you have?” This is a deliberate design choice.nsLocksis a map of per-path read-write mutexes. This is what makes the namespace operations concurrent (more on this below).
Namespace Locking
This is one of the subtler but more important parts of the implementation.
func (m *Master) acquireNamespaceLocks(path string, exclusive bool) func() {
parts := splitPath(path)
var locks []*sync.RWMutex
var exclusive_flags []bool
current := ""
for i, p := range parts {
current = buildPath(current, p)
lk := m.getOrCreateNsLock(current)
isLast := i == len(parts)-1
if isLast && exclusive {
lk.Lock()
exclusive_flags = append(exclusive_flags, true)
} else {
lk.RLock()
exclusive_flags = append(exclusive_flags, false)
}
locks = append(locks, lk)
}
return func() {
for i := len(locks) - 1; i >= 0; i-- {
if exclusive_flags[i] {
locks[i].Unlock()
} else {
locks[i].RUnlock()
}
}
}
}
Instead of one giant lock on the whole namespace (which would kill concurrency), GFS uses a lock per path component.
For an operation on /data/logs/access.log:
- Read-lock
/data - Read-lock
/data/logs - Write-lock
/data/logs/access.log(only if it’s an exclusive operation)
This means two operations on different files in different directories never block each other. Two creates in /data/logs/ and /data/processed/ run concurrently with zero contention.
The rename operation has to lock two paths, which risks deadlock if two renames swap the same paths. The fix:
paths := []string{src, dst}
sort.Strings(paths)
release1 := m.acquireNamespaceLocks(paths[0], true)
release2 := m.acquireNamespaceLocks(paths[1], true)
Sort the paths alphabetically and always lock in that order. Deadlock mathematically impossible. Classic.
Creating and Deleting Files
func (m *Master) createFile(path string) error {
release := m.acquireNamespaceLocks(path, true)
defer release()
m.mu.Lock()
defer m.mu.Unlock()
if _, exists := m.namespace[path]; exists {
return fmt.Errorf("file already exists: %s", path)
}
parent := parentPath(path)
pMeta, exists := m.namespace[parent]
if !exists || !pMeta.IsDirectory {
return fmt.Errorf("parent directory does not exist: %s", parent)
}
m.appendLog(OperationLogEntry{Op: OpCreate, Path: path})
m.namespace[path] = &FileMetadata{
Path: path,
SnapRefCount: make(map[ChunkHandle]int),
}
return nil
}
Two-step process: log the operation, then apply it. The log comes first, always. If the master crashes after logging but before updating the in-memory map, it replays the log on restart and the create happens then. Correct either way.
The delete is more interesting:
func (m *Master) deleteFile(path string) error {
// ...validation...
m.appendLog(OperationLogEntry{Op: OpDelete, Path: path})
meta.IsDeleted = true
meta.DeletedAt = time.Now()
hiddenName := fmt.Sprintf("%s%d_%s", DeletedPrefix, time.Now().UnixNano(), filepath.Base(path))
delete(m.namespace, path)
meta.Path = hiddenName
m.namespace[hiddenName] = meta
return nil
}
The file is not actually deleted. It’s renamed to a hidden path under /.deleted/. The original path immediately disappears from the namespace (clients can no longer find it), but the chunks still exist. The GC loop comes along later and actually frees the data.
Why lazy? Three reasons from the paper:
- Accidental deletion can be undone by just renaming it back, within the GC window
- Deletion is decoupled from the write path, so it never causes latency spikes
- The master can batch multiple deletions and process them efficiently
Allocating Chunks
func (m *Master) allocateChunk(path string) (ChunkHandle, []string, error) {
handle := ChunkHandle(atomic.AddUint64(&m.nextHandle, 1))
version := ChunkVersion(1)
locations := m.selectChunkServers(m.config.ReplicationFactor)
if len(locations) == 0 {
return 0, nil, fmt.Errorf("no chunkservers available")
}
m.chunkMeta[handle] = &ChunkMetadata{
Handle: handle,
Version: version,
}
m.chunkLocations[handle] = make(map[string]bool)
for _, addr := range locations {
m.chunkLocations[handle][addr] = true
}
meta.Chunks = append(meta.Chunks, handle)
m.appendLog(OperationLogEntry{Op: OpChunkAlloc, Path: path, Chunk: handle, Version: version})
return handle, locations, nil
}
When a client needs to write to a new part of a file, it asks the master to allocate a chunk. The master:
- Generates a new handle with an atomic increment
- Picks which servers should hold the replicas (using rack-aware placement)
- Records this in its metadata maps
- Logs it
- Returns the handle and server addresses to the client
The client then talks directly to those chunkservers to actually write the data.
Rack-Aware Server Selection
func (m *Master) selectChunkServers(count int) []string {
// Sort by rack first, then disk usage
sort.Slice(alive, func(i, j int) bool {
if alive[i].Rack != alive[j].Rack {
return alive[i].Rack < alive[j].Rack
}
return alive[i].DiskUsage < alive[j].DiskUsage
})
// Greedy rack-diverse selection
selected := make([]string, 0, count)
usedRacks := make(map[string]int)
for _, cs := range alive {
if len(selected) >= count { break }
if usedRacks[cs.Rack] == 0 || len(selected) >= len(usedRacks) {
selected = append(selected, cs.Address)
usedRacks[cs.Rack]++
}
}
// ...
}
For a replication factor of 3, you don’t want all 3 replicas on servers in the same rack. If the rack’s power switch dies, all your replicas go down simultaneously.
GFS’s rule: place at least 2 replicas on 2 different racks. This implementation goes further, it greedily picks servers from different racks first, preferring those with lower disk usage.
In Google’s real datacenters, “rack” maps to a physical top-of-rack switch. Inter-rack bandwidth is often the bottleneck, so there’s also a data-flow optimization that we’ll see in the write path.
6. Lease Management, The Heart of Consistency
Leases are how GFS achieves consistent writes without the master being involved in every single one.
type LeaseInfo struct {
Primary string
Expiry time.Time
Version ChunkVersion
}
When a client wants to write to a chunk, the master grants a lease to one of the chunkservers for that chunk. That server becomes the primary for the next 60 seconds. During this window:
- All writes to this chunk go through the primary first
- The primary assigns serial numbers to each mutation
- All replicas apply mutations in the same serial order
This guarantees that all replicas end up identical even if multiple clients are writing concurrently. The primary is the serialization point.
func (m *Master) grantLease(
handle ChunkHandle,
cm *ChunkMetadata,
locs map[string]bool,
) (string, []string, ChunkVersion, error) {
cm.Version++ // bump version before granting
version := cm.Version
// Notify all replicas of the new version
for addr := range locs {
go func(serverAddr string) {
client, _ := rpc.Dial("tcp", serverAddr)
defer client.Close()
args := &UpdateVersionArgs{Handle: handle, NewVersion: version}
client.Call("ChunkServerService.UpdateVersion", args, &UpdateVersionReply{})
}(addr)
}
expiry := time.Now().Add(m.config.LeaseTimeout)
m.leases[handle] = &LeaseInfo{
Primary: primary,
Expiry: expiry,
Version: version,
}
// ...
}
The version bump here is critical. Before granting the lease, the master increments the chunk’s version and pushes it out to all replicas. Any chunkserver that was offline and missed this bump now has a stale version. The next time it heartbeats in, the master detects the version mismatch and tells it to throw away its copy.
this is the stale replica detection mechanism. It’s elegant because it piggybacks on the existing heartbeat and lease-grant flow.
7. Snapshots, Copy-on-Write
func (m *Master) snapshotFile(src, dst string) error {
// Revoke all leases on source chunks
for _, handle := range srcMeta.Chunks {
delete(m.leases, handle)
}
// Create destination metadata pointing at same chunks
dstMeta := &FileMetadata{
Path: dst,
Chunks: make([]ChunkHandle, len(srcMeta.Chunks)),
...
}
copy(dstMeta.Chunks, srcMeta.Chunks)
// Increment reference counts on all shared chunks
for _, handle := range srcMeta.Chunks {
srcMeta.SnapRefCount[handle]++
dstMeta.SnapRefCount[handle] = srcMeta.SnapRefCount[handle]
}
m.namespace[dst] = dstMeta
return nil
}
Snapshots are nearly instant. Instead of copying gigabytes of data, the master just creates a new metadata entry pointing at the same chunks, then bumps the reference counts.
The heavy lifting happens lazily, when someone actually tries to write to one of the shared chunks:
func (m *Master) copyOnWrite(path string, chunkIndex int) (ChunkHandle, error) {
meta.Chunks[chunkIndex]
oldHandle := refCount := meta.SnapRefCount[oldHandle]
if refCount <= 0 {
return oldHandle, nil // not shared, write directly
}
// Allocate a brand new chunk handle
newHandle := ChunkHandle(atomic.AddUint64(&m.nextHandle, 1))
// Tell each chunkserver to copy the old chunk to the new handle
for addr := range locs {
go func(serverAddr string) {
client, _ := rpc.Dial("tcp", serverAddr)
client.Call("ChunkServerService.LocalCopy", &LocalCopyArgs{
OldHandle: oldHandle,
NewHandle: newHandle,
}, &LocalCopyReply{})
}(addr)
}
// Update metadata to point at the new chunk
meta.Chunks[chunkIndex] = newHandle
meta.SnapRefCount[oldHandle]--
return newHandle, nil
}
The write triggers a “copy on write”, the chunkserver makes a local copy of the data, the new file gets its own independent chunk, and the original snapshot is completely unaffected. The snapshot never saw the write at all.
This is why SnapRefCount exists in FileMetadata. It’s the reference counter that tracks how many files are sharing a chunk and whether a copy is needed before a write.
8. Background Goroutines
Garbage Collection
func (m *Master) runGC() {
m.mu.Lock()
defer m.mu.Unlock()
// Phase 1: remove expired deleted files
for path, meta := range m.namespace {
if meta.IsDeleted && now.Sub(meta.DeletedAt) > m.config.GCDelay {
for _, handle := range meta.Chunks {
m.scheduleChunkDeletion(handle)
}
delete(m.namespace, path)
}
}
// Phase 2: find orphaned chunks not referenced by any file
referenced := make(map[ChunkHandle]bool)
for _, meta := range m.namespace {
for _, h := range meta.Chunks {
referenced[h] = true
}
}
for handle := range m.chunkMeta {
if !referenced[handle] {
m.scheduleChunkDeletion(handle)
delete(m.chunkMeta, handle)
}
}
}
GC runs in two phases. First, it purges files that were deleted more than GCDelay ago. Second, it finds any chunks that exist in the master’s metadata but aren’t referenced by any file, these are orphaned, perhaps from a partial operation or a crash mid-allocation.
scheduleChunkDeletion sends async delete RPCs to all chunkservers holding copies of the chunk. The chunkservers just remove the chunk from memory (in this implementation) or from disk (in the real thing).
This two-phase approach means GC never blocks the write path. Files are made invisible immediately on delete, but the actual cleanup happens asynchronously in the background.
Re-Replication
func (m *Master) checkReplication() {
for handle, cm := range m.chunkMeta {
locs := m.chunkLocations[handle]
currentReplicas := len(locs)
if currentReplicas < m.config.ReplicationFactor && currentReplicas > 0 {
var source string
for addr := range locs {
source = addr
break
}
targets := m.selectChunkServers(1)
for _, target := range targets {
if locs[target] { continue }
go func(t, s string, h ChunkHandle) {
client, _ := rpc.Dial("tcp", t)
client.Call("ChunkServerService.CopyChunk", &CopyChunkArgs{
Handle: h, SourceServer: s,
}, &CopyChunkReply{})
// update master's location map on success
}(target, source, handle)
break
}
}
}
}
When a chunkserver dies, all the chunks it was holding drop from 3 replicas to 2. This loop detects that and dispatches a copy job to bring them back up to 3.
It processes one chunk at a time to avoid overloading the network. In the real GFS, chunks closer to falling off a cliff (only 1 replica) would get priority over chunks with 2 replicas.
9. The Heartbeat, How the Master Knows Who’s Alive
func (m *Master) handleHeartbeat(args *HeartbeatArgs) *HeartbeatReply {
// Update server state
cs.LastHeartbeat = time.Now()
cs.DiskUsage = args.DiskUsage
cs.Alive = true
// Process chunk reports, rebuild location map
for _, report := range args.Chunks {
cs.Chunks[report.Handle] = report.Version
m.chunkLocations[report.Handle][args.ServerAddr] = true
// Stale detection: version mismatch?
cm, exists := m.chunkMeta[report.Handle]
if exists && report.Version < cm.Version {
reply.StaleChunks = append(reply.StaleChunks, report.Handle)
}
}
return reply
}
Every 500ms, each chunkserver sends the master a heartbeat with a list of all the chunks it’s currently holding (and their versions). The master does several things with this:
- Updates the location map, rebuilding it from scratch each time (remember, it’s not persisted)
- Detects stale chunks, if a server reports a chunk at version 3 but the master knows the chunk is at version 5, that server missed 2 lease grants while it was offline. Its copy is stale. The master tells it to delete that chunk.
- Detects server failures, if a heartbeat stops coming, the server is considered dead
The response back to the chunkserver can contain two things:
StaleChunks: chunks the server should delete because they’re outdatedChunksToDelete: chunks the GC wants cleaned up
10. The ChunkServer
If the master is the brain, the chunkservers are the muscles. They store data and serve it.
type ChunkServer struct {
mu sync.RWMutex
address string
rack string
masterAddr string
chunks map[ChunkHandle]*LocalChunk // in-memory chunk store
pendingData map[uint64][]byte // data pushed but not yet written
nextSerial uint64
config *Config
listener net.Listener
}
pendingData is a staging buffer for the two-phase write protocol. Data arrives via PushData and sits here until a WriteChunk or AppendChunk command tells it to commit. The uint64 key is a DataID, a unique token the client uses to reference the data it pushed.
Pipelined Data Push
func (cs *ChunkServer) pushData(dataID uint64, data []byte, forwardTo []string) error {
// Store locally in the staging buffer
cs.pendingMu.Lock()
cs.pendingData[dataID] = make([]byte, len(data))
copy(cs.pendingData[dataID], data)
cs.pendingMu.Unlock()
// Immediately forward to the next server in the pipeline
if len(forwardTo) > 0 {
next := forwardTo[0]
remaining := forwardTo[1:]
client, _ := rpc.Dial("tcp", next)
client.Call("ChunkServerService.PushData", &PushDataArgs{
DataID: dataID,
Data: data,
ForwardTo: remaining,
}, &PushDataReply{})
}
return nil
}
This implements chain replication, one of GFS’s cleverest tricks.
Imagine 3 servers: A, B, C. The client pushes data to A. A starts forwarding to B immediately while it’s still receiving. B starts forwarding to C immediately. All three links are saturated simultaneously. Compare this to the client broadcasting to all three in parallel, that would require the client’s uplink to carry 3x the data.
With pipelining, the total transfer time for B bytes is approximately B/bandwidth + 2 * latency instead of 3 * B/bandwidth. At 100 Mbps with 1 MB of data, that’s about 80ms instead of 240ms.
The forwardTo slice shrinks by one at each hop. Server A gets [B, C], forwards to B with [C], B forwards to C with [], C sees an empty list and stops.
Write Path, Primary Coordination
func (cs *ChunkServer) writeChunkAsPrimary(
handle ChunkHandle,
dataID uint64,
offset int64,
secondaries []string,
version ChunkVersion,
) error {
data, ok := cs.getPendingData(dataID)
if !ok {
return fmt.Errorf("no pending data for ID %d", dataID)
}
serialNum := atomic.AddUint64(&cs.nextSerial, 1)
// Apply locally first
if err := cs.applyMutation(handle, MutationWrite, data, offset, serialNum, version); err != nil {
return err
}
// Fan out to all secondaries in parallel
errCh := make(chan error, len(secondaries))
for _, sec := range secondaries {
go func(addr string) {
client, _ := rpc.Dial("tcp", addr)
client.Call("ChunkServerService.ApplyMutation", &ApplyMutationArgs{
Handle: handle,
Type: MutationWrite,
Data: data,
Offset: offset,
SerialNum: serialNum,
Version: version,
}, &ApplyMutationReply{})
// send error or nil to channel
}(sec)
}
// Wait for ALL secondaries to confirm
for i := 0; i < len(secondaries); i++ {
if err := <-errCh; err != nil {
return err
}
}
return nil
}
After data has been pushed to all servers, the client sends a WriteChunk command to the primary. The primary:
- Pulls the data out of its
pendingDatabuffer - Assigns a monotonically increasing
serialNum, this is the mutation’s place in the global order - Applies the mutation locally
- Fans out
ApplyMutationRPCs to all secondaries in parallel (goroutines + channel) - Waits for all secondaries to confirm
- Returns success (or the first error) to the client
Every secondary applies mutations in the order of their serialNum. Even if RPCs arrive out of order, all servers end up applying them in the same sequence, guaranteeing all replicas stay identical.
If any secondary fails, the entire write fails. The client will retry, and the paper says to just retry from the data-push step.
Append Path, Where GFS Gets Really Cool
func (cs *ChunkServer) appendChunkAsPrimary(
handle ChunkHandle,
dataID uint64,
secondaries []string,
version ChunkVersion,
) (int64, error) {
data, ok := cs.getPendingData(dataID)
...
cs.mu.Lock()
chunk := cs.chunks[handle]
// Check if append would overflow the chunk
if chunk.Size+int64(len(data)) > cs.config.ChunkSize {
chunk.Size = cs.config.ChunkSize // pad to full size
chunk.Checksums = computeBlockChecksums(chunk.Data[:chunk.Size])
cs.mu.Unlock()
return -1, fmt.Errorf("CHUNK_FULL")
}
// THE KEY STEP: primary picks the offset
offset := chunk.Size
cs.mu.Unlock()
// Apply at that offset locally and on all secondaries
// ... same fan-out pattern as write ...
return offset, nil
}
The magic of atomic record append is in the line offset := chunk.Size.
The primary serializes all concurrent appends by picking the offset while holding a lock. No matter how many clients are appending simultaneously, they each get a different offset assigned by the primary, and all secondaries write at that exact same offset. The result: multiple concurrent writers, zero overlap, zero coordination needed by the clients themselves.
When the chunk is too full for an append, the server returns CHUNK_FULL. The client then allocates a new chunk and retries. The paper notes that the abandoned chunk might have some padding bytes at the end from other concurrent appenders, that’s fine, the client just moves on.
This is why append is capped at ChunkSize / 4 (16 MB with 64 MB chunks). You don’t want a single append that’s 63 MB failing and forcing an almost-empty new chunk to be allocated.
Applying Mutations
func (cs *ChunkServer) applyMutation(
handle ChunkHandle,
mutType MutationType,
data []byte,
offset int64,
serialNum uint64,
version ChunkVersion,
) error {
cs.mu.Lock()
defer cs.mu.Unlock()
chunk := cs.chunks[handle]
// Grow the data buffer if needed
needed := offset + int64(len(data))
if needed > int64(len(chunk.Data)) {
newData := make([]byte, cs.config.ChunkSize)
copy(newData, chunk.Data)
chunk.Data = newData
}
copy(chunk.Data[offset:], data)
if needed > chunk.Size {
chunk.Size = needed
}
// Recompute checksums for affected blocks
chunk.Checksums = computeBlockChecksums(chunk.Data[:chunk.Size])
return nil
}
This is the actual write. Bytes get written at the specified offset, the size is updated, and the checksums for the affected blocks are recomputed. Simple as that.
Both the primary and secondaries call this same function. The primary calls it directly; the secondaries call it via the ApplyMutation RPC.
11. The GFS Client
type GFSClient struct {
masterAddr string
locationCache map[ChunkHandle]*CachedLocation
cacheMu sync.RWMutex
cacheTimeout time.Duration
dataIDCounter uint64
}
The client library is what application code actually uses. It knows how to talk to both the master (for metadata) and chunkservers (for data).
Location Cache
type CachedLocation struct {
Primary string
Secondaries []string
Version ChunkVersion
CachedAt time.Time
}
The client caches chunk locations for 60 seconds. This is one of GFS’s key performance tricks. Once a client has been told “chunk #42 is on server A, B, C, and A is the primary”, it doesn’t need to ask the master again for a minute. For large sequential reads of a file, the client hits the master once per chunk and then goes direct.
If a read or write fails (server down, stale replica), the client calls invalidateCache(handle) and re-queries the master for fresh locations.
The Read Path
func (c *GFSClient) Read(path string, offset int64, length int) ([]byte, error) {
remaining := length
currentOffset := offset
for remaining > 0 {
chunkIndex := int(currentOffset / chunkSize)
chunkOffset := currentOffset % chunkSize
// Get chunk handle from master
handle, _ := c.getChunkHandle(path, chunkIndex)
// Get locations (from cache or master)
primary, _, _, _ := c.getLocations(handle)
// Read directly from chunkserver
readLen := min(int(chunkSize-chunkOffset), remaining)
data, _ := c.readFromServer(primary, handle, chunkOffset, readLen)
result = append(result, data...)
remaining -= len(data)
currentOffset += int64(len(data))
if len(data) < readLen {
break // end of file
}
}
return result, nil
}
The read path handles files that span multiple chunks transparently. It:
- Computes which chunk the current offset falls in
- Gets the chunk handle from the master (or cache)
- Gets the server locations (from cache)
- Reads directly from the primary chunkserver
- Loops until all
lengthbytes are read
The master is only involved in step 2, and only when the cache is cold. Most of the time, reads go straight to chunkservers.
The Write Path
func (c *GFSClient) Write(path string, offset int64, data []byte) error {
written := 0
for written < len(data) {
currentOffset := offset + int64(written)
chunkIndex := int(currentOffset / chunkSize)
chunkOffset := currentOffset % chunkSize
// Get or allocate the chunk
handle, _ := c.getOrAllocateChunk(path, chunkIndex)
// Get primary and secondaries
primary, secondaries, version, _ := c.getLocations(handle)
// 1. Push data through the pipeline
dataID := atomic.AddUint64(&c.dataIDCounter, 1)
allServers := append([]string{primary}, secondaries...)
c.pushData(allServers[0], dataID, chunk, allServers[1:])
// 2. Send write command to primary
c.writeChunk(primary, handle, dataID, chunkOffset, secondaries, version)
written += writeLen
}
return nil
}
Clean two-phase protocol:
- Push phase: pipeline the data through all servers so everyone has it in their staging buffer
- Control phase: tell the primary to commit it at the specified offset
The data and control flows are completely separate. The client pushes data through the chain A→B→C (using available bandwidth), then sends the write command via a short control message directly to the primary.
The Append Path
func (c *GFSClient) Append(path string, data []byte) (int64, error) {
maxAppendSize := int64(DefaultChunkSize / 4)
if int64(len(data)) > maxAppendSize {
return 0, fmt.Errorf("append data exceeds max size %d", maxAppendSize)
}
for retry := 0; retry < maxRetries; retry++ {
// Find the last chunk (or allocate one)
handle, _ := c.getLastChunk(path)
primary, secondaries, version, _ := c.getLocations(handle)
// Push data, then send append command to primary
dataID := atomic.AddUint64(&c.dataIDCounter, 1)
c.pushData(...)
offset, err := c.appendChunk(primary, handle, dataID, secondaries, version)
if err == "CHUNK_FULL" {
// Allocate a new chunk and retry
c.allocateChunk(path)
continue
}
return offset, nil
}
return 0, fmt.Errorf("append failed after retries")
}
The append path is a retry loop. Most of the time it just works. When the last chunk is full, it allocates a new one and retries. The returned offset tells the client exactly where their record landed, useful for building readers that know where to look for specific records.
12. The Demo, Putting It All Together
Okay enough theory. Let’s actually run the thing.
Boot Sequence
// 1. Start master
master := NewMaster(config)
go master.Start()
time.Sleep(300 * time.Millisecond)
// 2. Start 5 chunkservers across 3 racks
racks := []string{"rack1", "rack1", "rack2", "rack2", "rack3"}
for i := 0; i < 5; i++ {
servers[i] = NewChunkServer(config, master.address, racks[i])
go servers[i].Start()
}
// 3. Wait for heartbeats to register servers
time.Sleep(2 * time.Second)
The time.Sleep(2 * time.Second) after starting chunkservers is important, the master only knows about servers after they send their first heartbeat. Before that, it has nobody to assign chunks to.
Concurrent Appenders (Test 4)
numAppenders := 10
var wg sync.WaitGroup
for i := 0; i < numAppenders; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
record := fmt.Sprintf("record-%02d|pid=%d|ts=%d\n", n, os.Getpid(), time.Now().UnixNano())
offset, err := client.Append("/data/logs/concurrent.log", []byte(record))
offsets[n] = offset
appendErrors[n] = err
}(i)
}
wg.Wait()
Ten goroutines, all appending to the same file simultaneously. Without GFS’s atomic record append, you’d need explicit locking between them. With it? They just append. Each gets a unique offset, none of them overlap, all records land intact.
This is the “producer-consumer queue” use case from the paper. Multiple MapReduce jobs can append their outputs to the same result file without coordinating with each other.
Snapshot Test (Test 5)
client.Snapshot("/data/logs/access.log", "/data/logs/access_backup.log")
client.Write("/data/logs/access.log", int64(len(testData)), newData)
snapData, _ := client.Read("/data/logs/access_backup.log", 0, len(testData))
// snapData should still equal original testData
Snapshot creates the copy (nearly instant, just metadata). Then we write new data to the original file, which triggers copy-on-write on the affected chunk. The snapshot remains unchanged because it now has its own independent copy of that chunk.
13. What’s Different From the Real GFS
This implementation captures all the core concepts from the paper, but there are a few things the real GFS does that this simulation skips:
Persistence to disk: Chunks live in memory here. The real GFS writes each chunk as an actual Linux file on the chunkserver’s disk. The master’s namespace and operation log are flushed to disk (and replicated to shadow masters).
Network-aware pipeline routing: The real GFS estimates network distance from IP addresses and routes the push pipeline along the shortest path. Here, the pipeline just goes in the order given.
Lease extension via heartbeats: Primaries that are actively serving writes can ask to extend their lease by piggybacking on heartbeat messages. This implementation uses fixed 60-second windows.
Operation log flushing: The real master flushes its log to disk (and to replicated remote machines) before responding to clients. Our appendLog is in-memory only.
Shadow masters: Real GFS has shadow masters that can serve read-only metadata queries even if the primary master is down. Not implemented here.
That said, the fundamental mechanisms are all here: chunk splitting, replication, leases, serial mutation ordering, pipelined data push, atomic record append, copy-on-write snapshots, lazy GC, and stale replica detection.
14. Data Flow Diagram
Here’s the full flow for a write:
sequenceDiagram
participant Client
participant Master
participant A as Chunkserver A
participant B as Chunkserver B
participant C as Chunkserver C
Client->>Master: GetChunkLocations
Master-->>Client: primary=A, secondaries=B,C
Client->>A: PushData
A->>B: forward data
B->>C: forward data
Client->>A: WriteChunk
A->>B: Apply write
A->>C: Apply write
B-->>A: OK
C-->>A: OK
A-->>Client: OK
The master is only touched once (step 1). Everything else goes directly between the client and chunkservers. This is why GFS can scale to hundreds of clients without the master becoming a bottleneck.
Conclusion
GFS is one of those systems where the design feels obvious in hindsight, and that’s the mark of a great paper. The single master simplifies everything. Leases eliminate the need for master involvement in every write. Lazy deletion makes the system more forgiving. Checksums catch corruption silently.
The decisions that seem counterintuitive, using such huge chunks, not caching file data on the client, rebuilding chunk locations from heartbeats instead of persisting them, all make perfect sense once you internalize the target workload: huge sequential reads and appends, hundreds of concurrent clients, thousands of commodity machines where failures are normal.
If you made it this far, congratulations! Here’s a brief cheat sheet for quick reference, on what we built today:
| Paper Concept | Implementation |
|---|---|
| Chunk handles & versions | ChunkHandle, ChunkVersion with atomic counter |
| Master metadata | FileMetadata, ChunkMetadata in RAM |
| Operation log | OperationLogEntry logged before every mutation |
| Chunk size (64 MB) | DefaultChunkSize config |
| Checksums (per 64 KB block) | computeBlockChecksums with CRC32 |
| Namespace locking | Per-path RWMutex with hierarchical locks |
| Lazy deletion | Rename to /.deleted/ + GC loop |
| Chunk replication | Rack-aware selectChunkServers |
| Leases | LeaseInfo with 60s timeout, primary coordination |
| Stale replica detection | Version mismatch via heartbeat reports |
| Snapshots | Copy-on-write via SnapRefCount |
| Re-replication | checkReplication background loop |
| Client location cache | CachedLocation with TTL |
| Two-phase write | Push data → Primary commits |
| Pipelined data push | forwardTo chain in PushData |
| Atomic record append | Primary picks offset, all replicas apply same order |
| Heartbeat protocol | 500ms interval, chunk reports, stale detection |
| Garbage collection | Two-phase GC: expired files → orphaned chunks |
In the next blog in this paper implementation series, I’ll implement the Amazon Dynamo paper. Stay tuned! Subscribe to the newsletter if you haven’t yet.